
Xss 攻击向量解析的探析
1@ 前言
当利用编码来绕过有关 xss 的 waf 的时候,有时我们构造的 payload 得不到执行。纵然你的编码方式是对的,但是如果对应的解析器不解析你的攻击向量,也是徒劳的。这时候我们就需要比较清晰的了解自己的 payload 所遵守的解析策略与经历的解析流程,然后构造出更加有针对性的攻击向量。
2@ 基础铺垫
在了解一个 payload 解析流程之前,我们需要先熟悉一些用到的基础知识。
2.1 HTML字符实体
在 HTML 中,字符实体其实就是转义序列,一般是为了正确显示保留,如 ‘<’**, **‘>’, 空格等。HTML 中的实体转义格式有以下两种:
Entity name (实体名称)
格式 : &实体名;
eg : < (less than)表示 ‘<’
Entity Number (实体编号)
格式 : &实体编号;
其中实体编号可以 是 16 进制格式 &#x 开头,或者 10 进制格式的 &# 开头。
eg : A 表示字符 ‘A’
2、 JS 中的 unicode 表示
格式 :\u + 16 进制的 unicode 编码
eg : \u5b89 表示汉字 安
3@ 攻击向量经历的三种解析
1、HTML 解析
原版的 HTML 解析规则戳这。
eg : <a href="http://www.baidu.com">text</a>
联想一下我们学过的数电,可以视 HTML 解析器为一个状态机,遍历获得的字符,按照规则进行状态的转换。以上面的例子:
当碰到 < 字符的时候,就会转换到标签开始状态 (Tag open state)【前提是紧跟字符不为 **/**】
然后跳转到 标签名状态(Tag name state) 【对应例子里面的 a 】
. . . . . .
进入数据状态 (Data state) 【对应例子里面的 text 】, 在刚进入这个状态时,释放当前标签的 token 【对应例子里面的 a 标签的前部分】。在数据状态时,每发现一个完整的标签,就会释放一个 token.
那么,是否存在这样一个位置状态,它可以将我们的字符实体解析并赋予本来的非字符的特殊意义(如 <表示 **<**可以当标签开始符来对待,然后让其中的脚本执行)? 答案是:没有。这就与 HTML 解析 规则有关。我们再拿一个例子来讲:
<div><script>alert(1);</script></div>
因为 div 标签开始后,解析器还是在数据状态,不会将这个字符引用转换为 ‘标签开始状态’,所以就可以保证我们得到的字符实体引用只会被解析为单纯的数据,而没有特殊意义,从而从一定程度上杜绝了一些风险。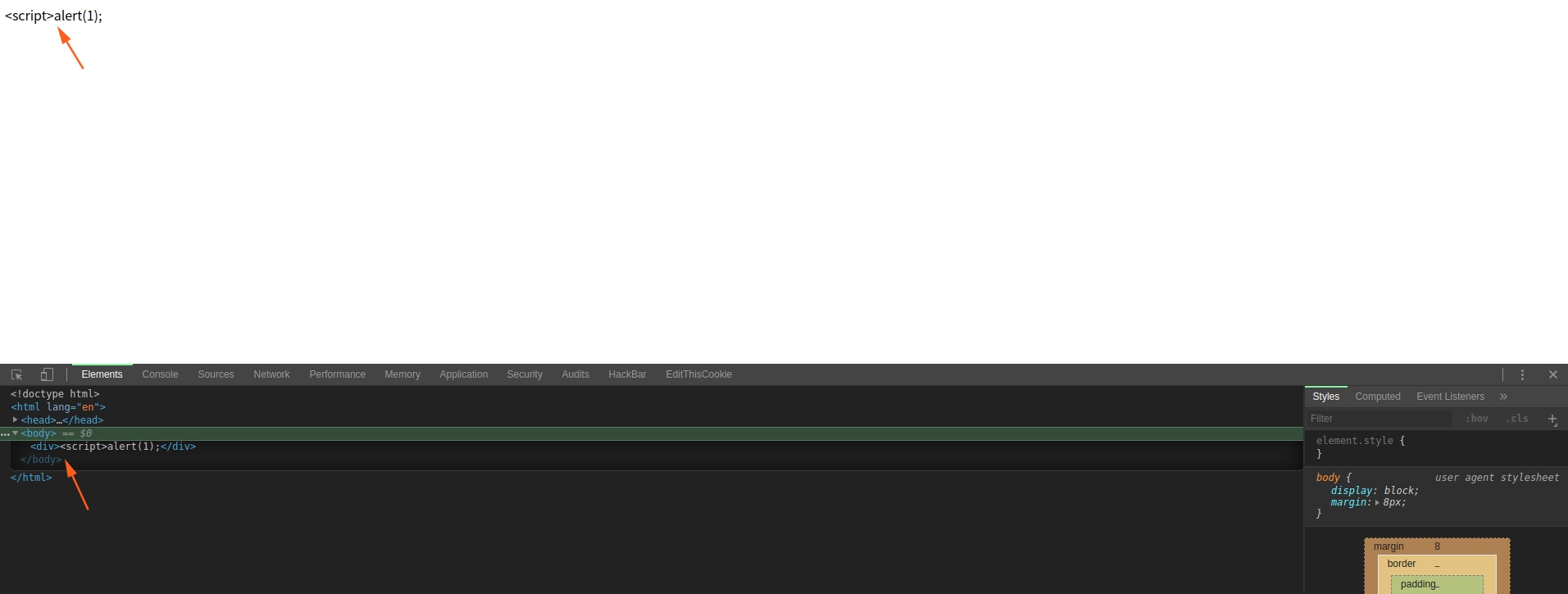
从图中我们可以看出来,’<’ 标签已经被转义,但是只是作为纯字符输出在页面中。之后的 由于未配对成功而被解析器去除。
而在 HTML 中也并不是所有位置都会解析转义字符引用,有三种情况下会转义:
数据状态的解析
<div><></div>
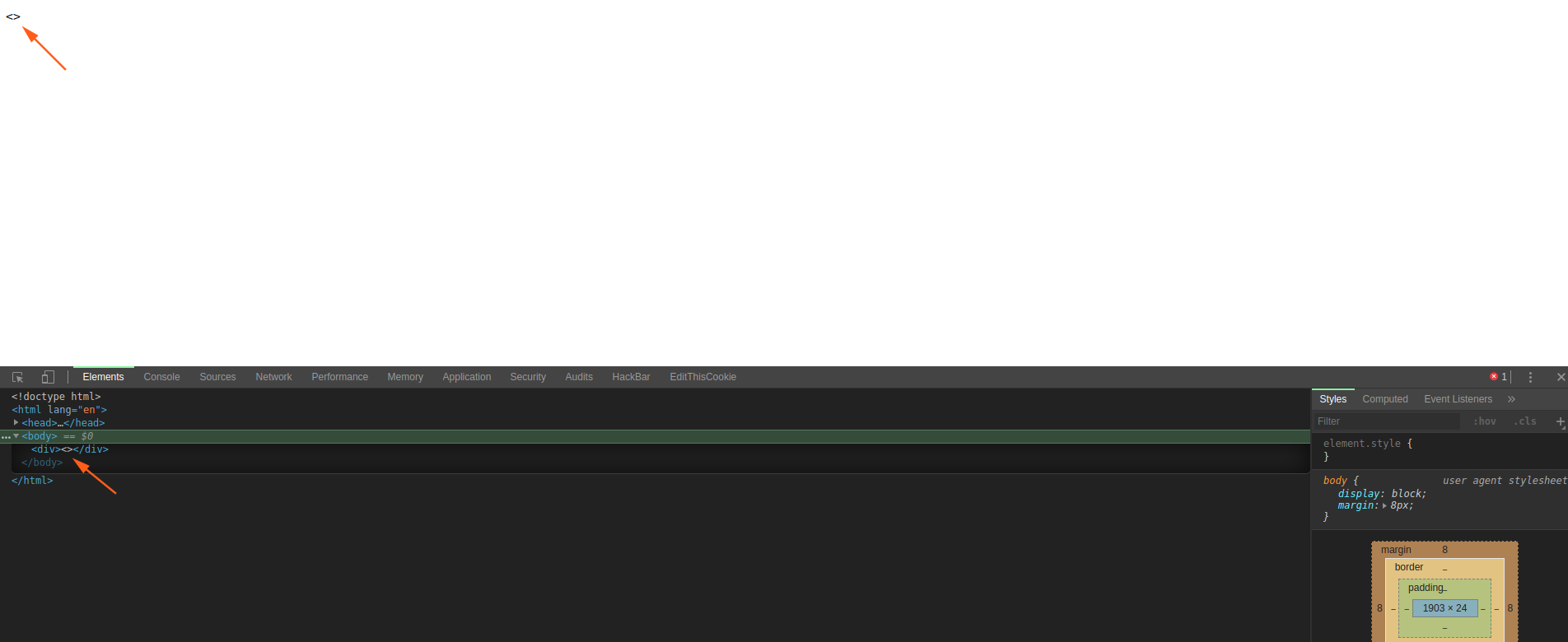
可以看到字符引用被解析。
属性值中的解析
<a href="javascript:alert(1)"></a>

可以看到 ‘(‘ 被解码。
RCDATA状态下的字符引用
这时我们需要先了解下 HTML 中的 5 类元素
1 | |
由于 RCDATA 状态中可以转义字符实体,那么在像 textarea title 等标签中就可以字符引用。这里 还有一个特殊的点就是在 RCDATA 元素标签 的内容中,遇到 < 后,会进入 RCADATA小于号状态,如果紧接着不是/字符的话,就会返回到 RCDATA状态。那么也就是说在 textarea或者title标签中只能认识并解析的标签只有对应的 或者 ,不会有新标签的产生,也就杜绝了脚本的执行。例如:
1 | |
是不会执行的。
2、URL 解析
同样的,URL 解析器依旧可以看做一个状态机,其解析规则在这里。这里只提几个 xss_payload 能涉及到的地方。
1、首先,资源类型必须是大写字母或者小写字母,否则会进入到无状态类型。那首先就要求资源的协议要保证格式完全的正确,譬如使用 javascript: 伪协议时不能使用编码来绕过,因为这会让 URL 解析器跳转到 ‘ 无类型 ’状态,导致资源不能正确解析,我们构造的 payload 也就不能得到正确的执行,我们来看看下面的例子:
<a href="%6a%61%76%61%73%63%72%69%70%74:alert(1)">text</a> 编码了 javascript,可以看到无法正确执行。

从图中可以看出,得到的跳转地址是 **http://localhost/javascript:alert(1)**,原因就是没有正确的识别资源的协议类型,拼接到了默认地址的后面,导致 payload 无法执行。
2、其次,URL 编码过程使用的是 UTF-8 编码,如果给 URL 进行别种方式的编码,会导致 URL 解析器不能正确识别。
HTML 中的两种 URL资源的执行
我们可以利用伪协议来进行 xss 的反射攻击,而在HTML 标签中有两种 url 的连接类型,一种是 src,一种是 href,我们先来看看两者的区别
1、src
src 适用于替换当前元素,是 source 的缩写,指向外部资源的位置,指向的内容会 自动的 嵌入到文档中标签的位置。请求 src 资源的时候会将其指向的资源下载并应用到文档内。例如 js 脚本,img 图片,frame 元素等。
2、href
href 是 Hypertext Reference 的缩写,指向网络资源的所在位置,是与该页面有关联的,是引用。
src与 href 的主要区别就是 一个是引入,一个是引用。
之前在很多地方看到 payload 都有这种 src 引用的格式
<img src="javascript:alert(0);">
但是现在在 Chrome 与 Firefox 上实验了下都不能执行。原因就是当下的一部分浏览器为了防止恶意代码的注入,已经禁用了 src 属性的 javascript 的伪协议。我们还有一种引入外部 js 文件的 src 利用方式:
<script src="evil.js"></script>
其中 evil.js 中的内容为
1 | |
3、 Javascript 解析
详见 javascript 的解析规则
因为 js 脚本一般是内嵌在 HTML 页面中的,所以 javascript 的解析容易与 HTML 解析搞混了。Javascript 的解析需要注意的点有下面两点:
script 标签的解析
在之前,我们提到过 HTML 中的 5 类元素,其中 script 标签属于 原始文本数据,。它有个特别的解析属性就是虽然内嵌在了 HTML 界面的数据状态,但是仍然不能解析字符引用。看看下面这个例子:
1 | |
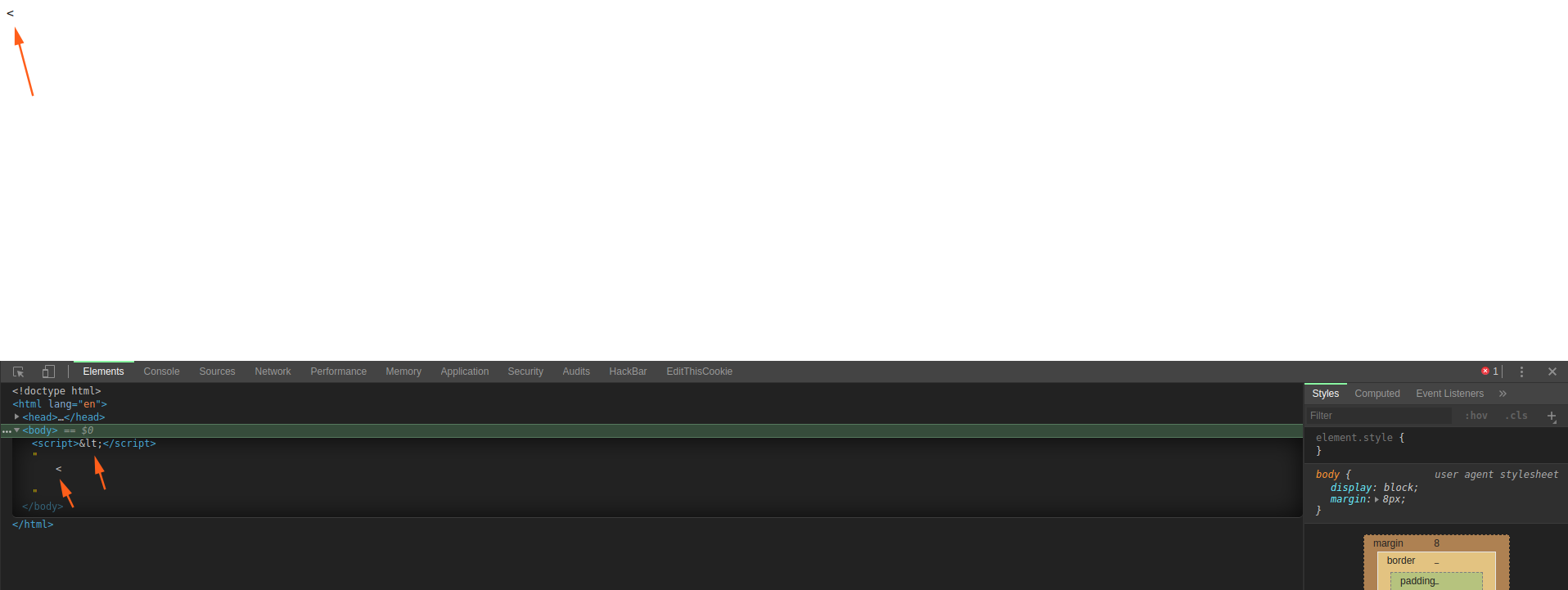
可以看到,里面的字符引用并没有被解码。
unicode 字符编码的解析
在之前的基础铺垫的时候提到了 js 中 unicode 的编码问题,那么它们在脚本的什么位置会被解析?又会被解析成什么意思?unicode 大致有以下三个位置会被解析,但是解析的意义有些许不同。
1、字符串中
unicode 放在字符串中的时候会被解析,但是只是会解析为常规的字符,不会解释为破坏上下文的特殊意义的字符。请看下例子:
1 | |
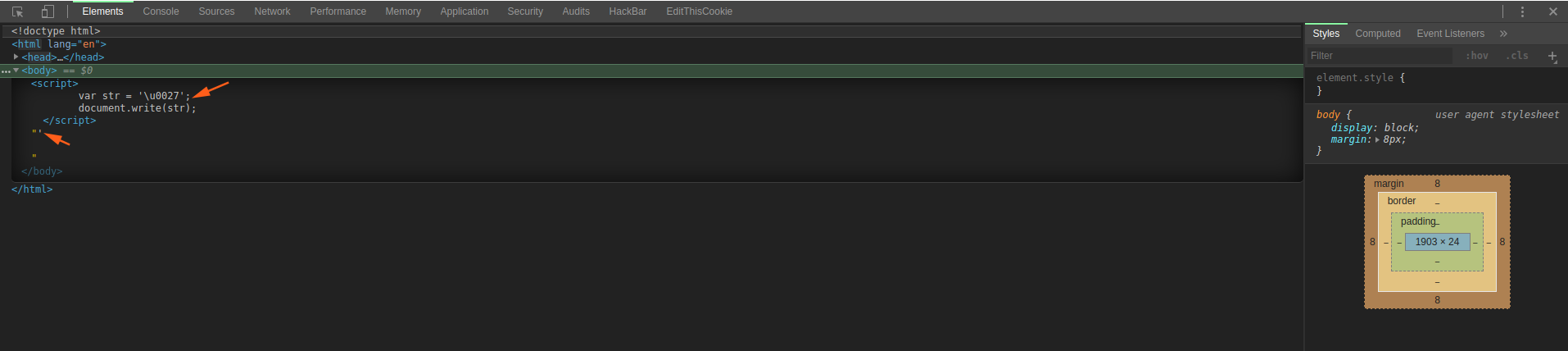
可以看到,被编码的单引号只是解释为了单纯的字符,没有破坏 js 的上下文。
2、标识符中
标识符包括函数名,属性名等。如果使用 unicode 编码这些数据的话,会被正确解释为上下文中的标识符,可以正确的运行。看下面这个例子:
1 | |
注意这里只编码了 document 和 write,并没有编码点号,因为测试结果显示无法编码点号进行执行,但这并不影响我们探测,因为一般利用到的函数都等都只是单纯的字母拼接。
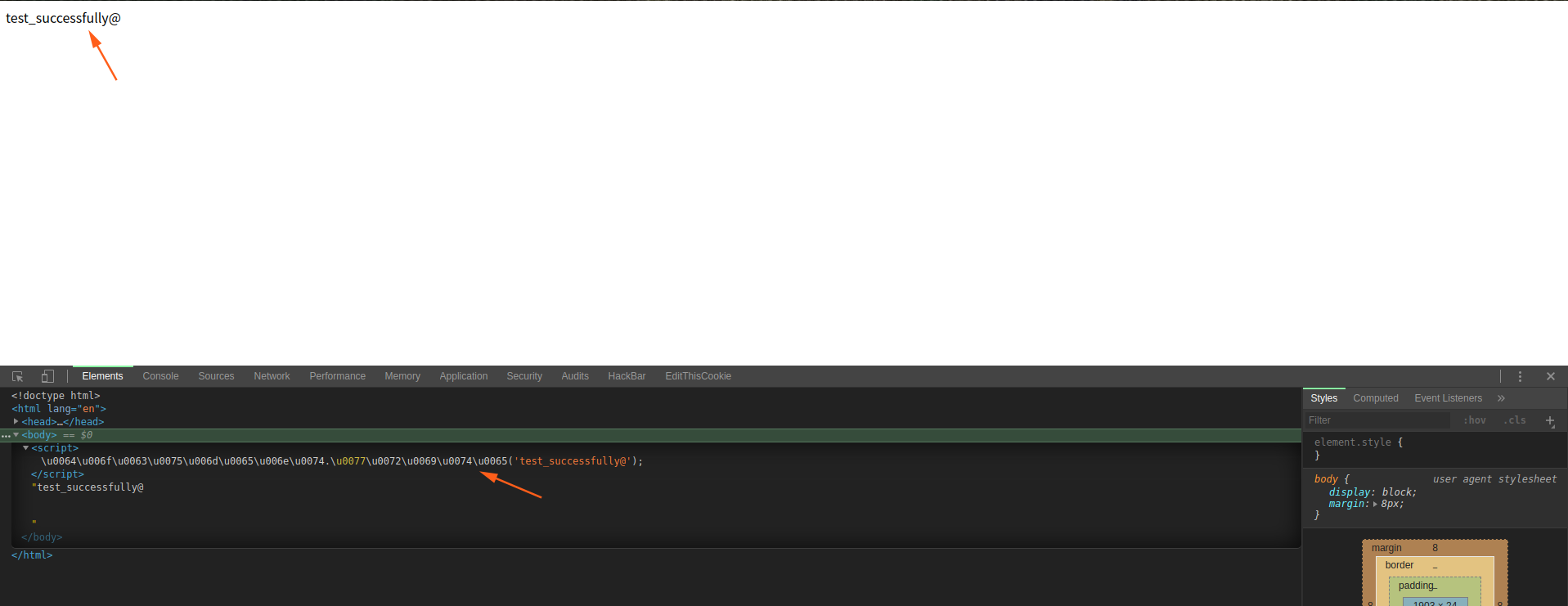
成功解码并执行了打印函数。
3、控制字符
当控制字符不在引号包围的时候,例如 ( ) ' "这些字符,裸露在文档外面进行 unicode 编码,js 解析器不能将它们正确的解析为控制字符,仅仅会被解码为标识符亦或是字符串,所以,想要成功执行一个 js 函数,就必须保证括号为 **()**,而不是 \u0028 \u0029.
综上,js 在解析 unicode 编码的时候,能赋予非字符意义的地方有且仅有标识符这一个位置。
4@ 解析流的顺序
前端这三大解析器一般是相互配合的,我们需要搞清楚他们配合的顺序,然后对应构造 payload ,才有可能正确的被解码执行。
一般的解析顺序如下:
1、HTML 解析
浏览器从网络堆栈中获取内容后,会触发 HTML 解析器根据解析规则(上文链接)对文章进行词法的解析,在这一步中,所有的合理的字符引用都会被解码【合理即能够被解析的位置放入字符引用】,解析完成后 DOM 树就被创建好了。
2、JS or URL 解析
为什么第二步的解析顺序不确定呢,这与文档资源类型的顺序有关。其中 Js 解析器 负责文档中内嵌脚本,unicode 编码等的解析,URL 解析器负责解析碰到的 URL 资源的解码。但位置不同,可能会造成不同的解析顺序。试看下两例:
1 | |
其中
脚本1先是由 url 解析器解析 href 中的资源,解析完成后进入 js 的上下文,所以 js 解析器再解析 js 的内容。
脚本2先是由 js 解析器解析 onclick 中的 unicode 编码,编码完成后发现参数是 url 的上下文,这时 url 解析器介入解析。
可以看到,不同的位置会导致不同的解析顺序。
5@ xss_payload 的练习
下面给出了常见的几种弹窗的方法,通过上面的阅读与学习,来判断下是否可以成功执行代码。
1 | |
解析
1、 无法执行,因为编码了协议
2、 可以执行,html 先解析字符实体编码 javascript ,url 解析器再解析 alert(2),位置与格式都允许。
3、 无法执行,因为协议被编码导致无法正确识别协议。
4、 无法执行,因为嵌在数据状态内,只能解析字符引用为普通字符串,无特殊意义。
5、无法执行,首先是因为在数据状态中只能将尖括号转义为字符串,其次 RCDATA 元素中不能嵌入新的标签,嵌入也无法执行代码。
更多例子附带答案,戳这
6@ 关于 svg 标签中解析 js 代码
上面写道 svg 标签属于外部元素,script 标签属于原是文本元素,而且也知道 script 标签里面是不能转义字符实体编码的,那么我们考虑一下下面这段代码是否可以弹窗:
<svg><script>alert(/xss/)</script></svg>
按我们上面理解的话,<script> 标签下不能解析字符引用,就算可以解析,圆括号这种被放在数据状态下的解码也只能成为字符串,并不能被解析为控制字符。
所以不能码?上图~

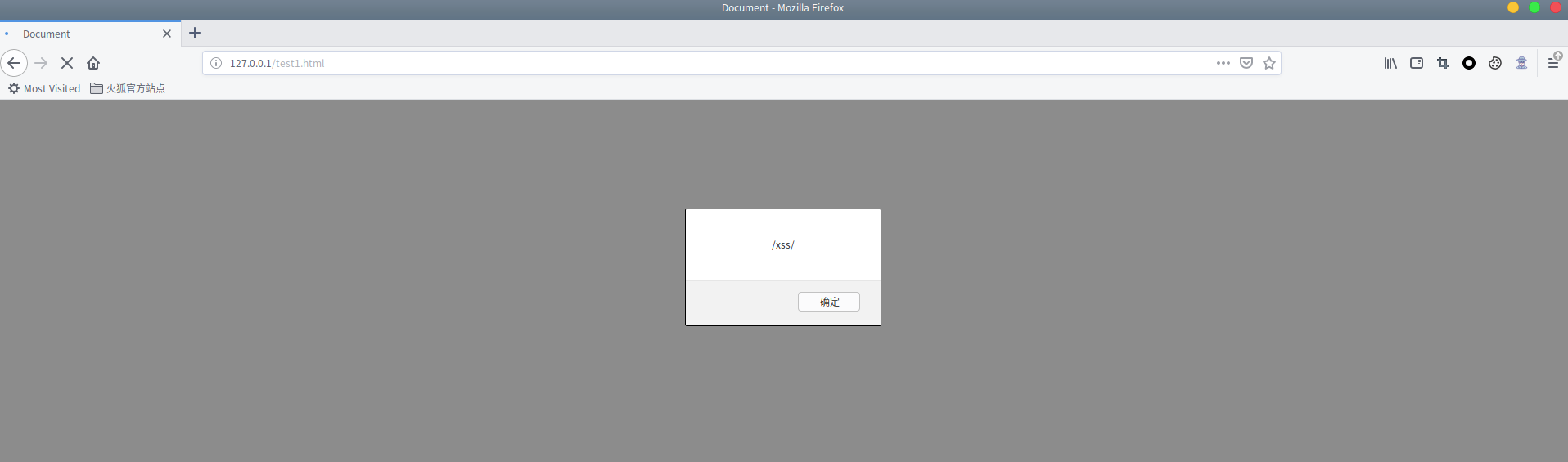
太夸张了,不仅解码了字符引用,还转换为了控制字符并且弹窗了~
按照上面的分析,问题绝对就在 svg 这个标签上面。
<svg>这个标签 使用 XML 格式定义图形,XML 会解析字符实体,而 w3c 上面给出的这段实例代码中也可以看出 xml 使用的端倪。
1 | |
那么为什么 script 标签可以被解析呢?原因就是 svg 标签支持 嵌入 script 标签。
这是支持 script 标签的文档借用引用文章作者的话来讲就是:
这个 payload 之所以可以执行是因为遵循了 svg 和 xml 的标准。
7@ 总结
理解一个漏洞的利用,需要也有必要挖的深些,这样才能更好的从攻与防的角度来构造攻击向量,亦或是根据攻击的思路来构造防御的 waf。
Reference:
1 | |
- 本文作者:rt
- 本文链接:https://rt95.gitee.io/2019/09/17/Xss%20%E6%94%BB%E5%87%BB%E5%90%91%E9%87%8F%E8%A7%A3%E6%9E%90%E7%9A%84%E6%8E%A2%E6%9E%90/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!